上一节我们已经完成了一个小例子,也基本了解了Elefant是怎么工作的,这节我们来点更深入的,顺便也能解决和我一样不能在GUI里修改路径的苦恼。
深入探究工作原理
点击Tools菜单下我们发现了Generate Code选项,选择该项,会提示你保存一个py文件,聪明的你可能已经猜到了,没错,我们刚才的一系列操作完全可以靠Python代码来实现。现在产生的这个文件,就是我们刚才一系列操作的代码!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| from elefant.framework.core.ports import Connect
from elefant.components.plots.wxinit import BeginWx, EndWx
import numpy
from elefant.components.plots.wxplot import CPlotScatter
from elefant.components.algorithms.svm.classification.SVMClassifications import NuSVMClassification
from elefant.kernels.vector import CGaussKernel
from elefant.components.data.readers.CSVData import CSVData
PlotResult = CPlotScatter()
PlotResult.plot1Title = 'Training Data'
PlotResult.plot2Title = 'Test Data'
Nu_SVM_classification = NuSVMClassification()
kernel = CGaussKernel()
kernel.blocksize = 128
kernel.scale = 0.3
Nu_SVM_classification.kernel = kernel
Nu_SVM_classification.nu = 0.3
TrainData = CSVData()
TrainData.delimiter = ','
TrainData.fileName = 'http://elefant-svn.developer.nicta.com.au/elefant/data/csv/train_cl.csv'
TrainData.labelColumns = 'last'
TrainData.maxRows = -1
TestData = CSVData()
TestData.delimiter = ','
TestData.fileName = 'http://elefant-svn.developer.nicta.com.au/elefant/data/csv/test_mu.csv'
TestData.labelColumns = None
TestData.maxRows = -1
Connect(TrainData, "Data", Nu_SVM_classification, "TrainData", "DenseMatrix")
Connect(TrainData, "Labels", Nu_SVM_classification, "TrainLabels", "DenseVector")
Connect(TestData, "Data", Nu_SVM_classification, "TestData", "DenseMatrix")
Connect(Nu_SVM_classification, "TestOut", PlotResult, "TestLabels", "DenseVector")
Connect(TestData, "Data", PlotResult, "TestDataXY", "DenseMatrix")
Connect(TrainData, "Labels", PlotResult, "TrainLabels", "DenseVector")
Connect(TrainData, "Data", PlotResult, "TrainDataXY", "DenseMatrix")
BeginWx()
TrainData.LoadData()
Nu_SVM_classification.Train()
TestData.LoadData()
Nu_SVM_classification.Test()
PlotResult.Plot()
EndWx()
|
我们简单分析一下这个代码,即使没有Python基础也可以轻松看明白(这也说明Python的设计是多么的简单,呵呵)。首先,把我们需要的组件 对应的类Import进来,然后初始化组件,配置其属性,前面在GUI里没办法改文件路径的现在可以改了吧,呵呵。其中最重要的就是Connect过 程,Connect方法做的工作就是我们用GUI将各个端口连接起来的工作,来看一下Connect,接受的参数依次为: src(源组件),srcPortName(源组件的端口),dest(目标组件),destPortName(目标组件的端口),protocol(两 个端口共用的协议),我们看到协议又是“DenseMatrix”,又是“DenseVector”一类的,据说是scipy包中的一些格式,我也不是很 了解,反正知道是矩阵和向量就成了。最后我们看被BeginWx()和EndWx()包围的就是我们在Execute Flow里配置的各组件方法的执行流程。我们打开终端,执行命令“python 文件名”让解释器执行这个py文件也可以得到同样的结果,这告诉我们GUI不是必须的,代码也可以干同样的事情,而且,代码更加灵活,后面我们可以看到,有的事情只能代码来干。。。
多数据源导入
前面讲到的例子中使用的都是CSV数据源,对于我们常用的Matlab数据源应该怎么处理呢,你一定想到了:拖个Matlab的reader组件不就搞定了,那你拖拖试试,发现了什么?什么!!!Matlab组件没有端口,OMG!
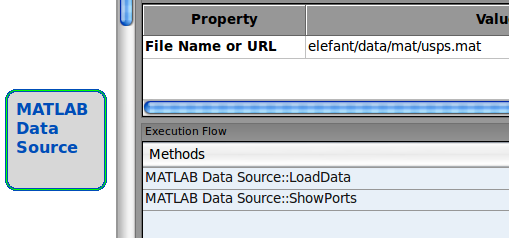
没有端口怎么传数据,不要急!GUI办不到的事情,我们只能求助于代码实现,细心的你也应该注意到,Matlab组件有一个“多余”的方法:ShowPort(),意思就是暴露自己的端口,这下你懂了吧。我们可以下载一个官方的Matlab数据源文件(大名鼎鼎的USPS数据集)研究一下。用Matlab打开,发现其结构是这个样子的:
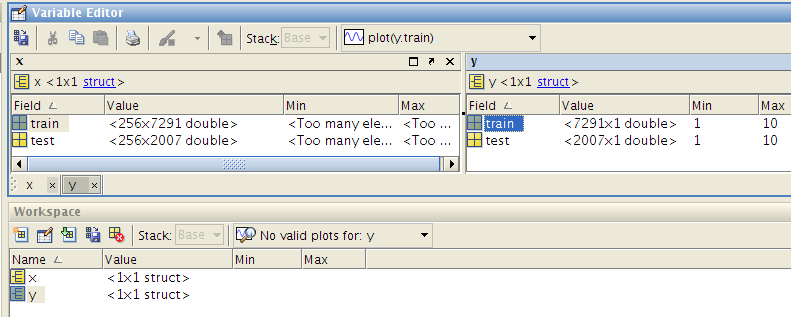
里 面有两个结构体x和y,每个结构体中包含train和test两个矩阵,自然x是训练和测试数据,y中是对应的标签,我们写一个小Python文 件进行测试,实例化一个Matlab组件,调用其ShowPort()方法,发现输出的端口名称是 “xtrain”,“xtest”,“ytrain”,“ytest”。原来是这么个规律,知道了端口名称,我们就可以知道对应的协议,知道了协议我们就 能获取协议上的数据,OK,拿到了数据,我们自己写Connect函数进行连接,这样就能使用Matlab数据源了。这当中还有一个问题,我们发现四个端 口上的协议名称全是“DenseMatrix”,也就是说标签对应的协议不是向量而是矩阵,这下麻烦大了,协议不一样就没办法Connect,翻官方文档 也是一无所获。。。经过一天的探索,我的解决方案是自己添加新的端口,指定其协议为“DenseVector”,将标签数据绑定其上,OK!可以看以下实 例代码:
1
2
3
4
5
6
7
8
| Data = MATLABData()
Data.fileName = '/home/pinky/Document/Elefant Datasets/test.mat'
Data.LoadData()
Data.AddPort('MyTrainLabels', 1).AddProtocol('DenseVector')
MyProtocol = Data.GetPort('MyTrainLabels').GetProtocol('DenseVector')
tmp = Data._GetData()[1]['ytrain']
tmp.shape = (tmp.shape[0], )
MyProtocol.SetData(tmp)
|
可以看到我们通过调用组件的函数AddProt(),AddProtocol(),添加端口和协议,通过获取原始的ytrain端口的数据,将其转 换为向量,然后通过SetData()将数据绑定到我们新建的这个端口上去。[PS 之所以产生这个问题,根源就是Matlab不区分向量和矩阵,向量在Matlab眼里是有一个维数是1的特殊矩阵(谁让人家名字都叫矩阵工作室呢~),而 Python则不一样了,它区分对待向量和矩阵,我们通过查看其shape属性就可发现,若是矩阵都是形如(5,3)这样的结果,若是向量则是(5,)这 样的结果,也就是第二维是缺失的,所以我们通过将其shape属性设置成向量这样即可达到目的。] 还有一些琐碎的问题,比如我发现Elefant内置的算法都要求数据格式为:一行为一个样本,即行数是样本数,列数是样本维数。所以我们需要修改原始 Matlab数据文件满足这个要求,要么就传进去以后再修改绑定数据。