前段时间抽空写了个Chrome插件,用来批量下载量子恒道的实时访客数据。下面这张图是当时把插件上传到Chrome Web Store时让提供的Promote图,作为一个毫无设计经验的孩子,弄成这样就不错了,起码这插件的作用一目了然嘛。如果有开淘宝店的卖家可以尝试,直接从商店安装:Chrome Web Store
这个名字嘛,党是Down的音译,不要和谐我!这篇博客就谈谈开发这个插件时的一些想法吧~

缘由
一般人估计量子恒道是啥也没听过吧?量子恒道是淘宝自带的店铺统计服务,分析店铺的访客啊流量啊什么的,类似Google Analytics。为啥会想到开发这么个非主流的东西呢?因为老婆现在的主业就是在家开淘宝店。话说老婆的淘宝店已经步入正轨,每天都会用这玩意关注店铺的流量。而量子恒道也挺变态的,店铺实时的来访数据只显示当天的,过了12点就清除,并且没有提供一个批量导出的功能。Google了一番想看看有没有现成的工具,发现搜出来的都是淘宝卖家在各种论坛上的抱怨,说明这需求还挺普遍的,所以还是自己开发这么个工具用来导出量子恒道的数据吧。
想法一:模拟登陆抓取网页
最先想到的方案自然是抓取网页了,用淘宝账号密码模拟登陆量子恒道,然后模拟一些请求抓取一页一页的网页,提取其中的数据整理下即可。但是一开始动手就发现问题没这么简单啊,查看量子恒道的首页会发现这个登陆框是一个iframe,如下图:
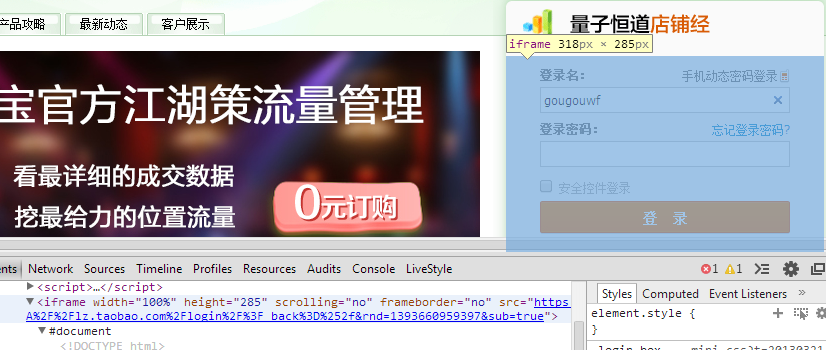
淘宝大概是专门做了一个网页用来登陆,网址是https://login.taobao.com/member/login.jhtml?_input_charset=utf-8&from=lzdp&style=minisimple&minipara=0,0,0&redirect_url=http%3A%2F%2Flz.taobao.com%2Flogin%2F%3F_back%3D%252f&rnd=1393660959397&sub=true,猜想应该是淘宝所有的服务都链接到这个网页去,然后登陆后拿到token再根据网址里的参数redirect_url重定向回各个具体的服务吧。那么既然如此,在程序里就直接访问这个iframe的网址,然后登陆后重定向回来就好。这么想着就开始试验,按照正常的步骤组装Post数据,加加header和cookie啊,发现提交表单后会重定向到同一个登陆页面,然后多了一个### 验证码框,欲哭无泪啊!估计是淘宝发现登陆的不是常用的IP地址会让你输验证码,安全啊!虽然说可以借助一些现成的库来识别这个验证码,不过我觉得为了弄个这再上图片识别太折腾了。与此同时我还发现,即便成功登陆还是问题多多。量子恒道的网站应该是SPA(Single Page Application),全部Ajax实现的。这一点可以从网址上得到确认,比如查看实时客户访问的页面网址http://lz.taobao.com/#recentvisitors/page:1,这是很典型的SPA。对于这类动态页面,抓起来也会有很多麻烦。所以最后的结论就是放弃这个方案了!
想法二:能不能hack一把API
既然量子恒道是全站Ajax,那肯定有自己的API系统了,那么能不能hack一下它的API呢,是不是也提供类似OAuth的机制呢?我用浏览器登陆量子恒道,打开“实时客户访问”页面,打开Chrome DevTools的Network标签,发现发出的请求是GET http://api.linezing.com/=/view/recent/~/~?p4p=0&limit=25&offset=0&_s=pb1vnj0p97### ******p6le25ve5bl4frvidjl8ec0o047q0b1cpsk&_c=OR.C%5B23%5D,而返回的数据是OR.C[23]([{"cnt":163},[{"im":"","is_baobei":1,"search_key":"","ip":"114.62.7.17","url":"http://item.taobao.com...,可以看到,里面正是我们需要的客户来访数据,只是这些数据被放入了OR.C[23]()这个函数里。根据网址里的参数_c=OR.C%5B23%5D,在Console里调用decodeURIComponent("%5B23%5D")发现这段乱码就是[23]。这是一个很明显的JSONP调用,这里_c的意思就是callback吧。再看看其他参数:
p4p=0:这个我表示也没搞懂。。。。limit=25:这个好理解,看看网页上每页只显示25条数据就明白,这个是每个请求包含的数据个数。offset=0:这个也很常见,从哪条数据开始拿,试试点击第二页会发现这个参数变成了25,即第二页从第25条(从0开始计算)数据开始。limit和offset是分页应用里非常常见的两个参数。_s=....:这么长一大串猜测就是所谓的token了,尝试去掉这个参数再请求发现已经没有任何结果返回了,那么这个参数就是至关重要的token!
观察返回的结果,"cnt:163"这个就是访客数据的总条数,那么我们完全可以这么去设计,第一个请求offset=0,limit=1,从返回的数据里拿到数据的总数,然后第二个请求offset=0,limit=cnt即可拿到所有的数据了。现在的问题就只有一个了:如何拿到参数_s。联想到_c代表callback,那么_s最有可能代表的就是session,带着这个推测打开Devtools的Resource标签,检查Cookie,发现果然有!如下图,名为lzsession的cookie就是我们要找的参数_s!
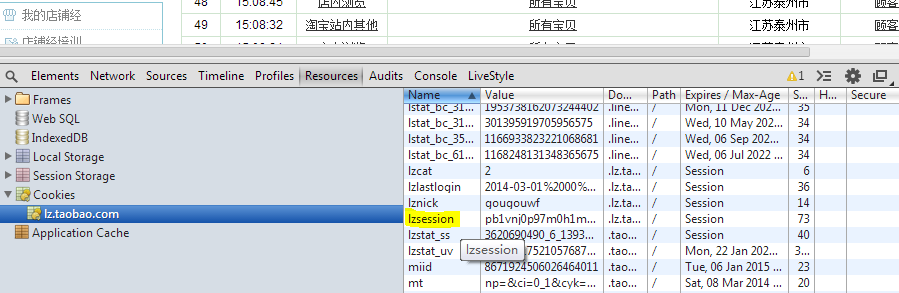
真是得来全不费功夫啊,但是登录问题又来了。尝试退出登录后发现这个cookie没了,很显然,不登陆是没有这个cookie的(session的意思也表示了登录才会有啊魂淡!)。绕了一大圈又回到登录这个老问题上了,肿么弄呢!这个时候我想到,干脆每次用户自己在浏览器端登录后自己拿到这个cookie的值,然后输到一个地方,然后下载。。。(一棵棵白菜飞过来,求别打脸。。。)但是,session也是有有效期的,也就是说,过一段时间这个session就无效了,所以你也不能指望用户提供一次session就万事大吉了。思前想后,最后的折中方案就是弄个Chrome插件吧,用户访问量子恒道的时候显示在地址栏,一旦用户登录,插件是可以拿到当前页面的所有cookie值的,这个时候用户点击完成数据的导出和下载。
Chrome插件搞起来
Chrome插件的资料网上还是挺多的,网上也有翻译好的中文版文档。简单来说,有的插件会一直显示在工具栏最右侧,有的则是显示在地址栏右侧,如下图:

高亮部分为这两种不同类型的插件,工具栏右侧的会一直显示,不管你访问什么网站,而地址栏的插件则是根据你访问的网站决定的,特定的网站才会显示,称为“Page Action”,这种正是我们需要的。Chrome插件的开发有一套自己的目录结构,可以借助Yeoman的chrome-extension-generator,但是我感觉挺复杂的,反正这个插件比较小,也不需要压缩JS/CSS之类的,Yeoman生成的如此庞大的Gruntfile有点小题大做。后来发现有一个叫extensionizr的网站,简单的点选一下你想要的插件设置即可下载一个Chrome插件的开发模板,这里也推荐一下。

这篇文章不打算详述Chrome插件的开发过程,我只说说其中几个比较重要的概念。
popup.html/popup.js:顾名思义,这个就是你点击插件图标所弹出的网页,这就是一个普通的网页,但是注意,它是没法访问你当前打开网页的内容的,即它没法拿到量子恒道的cookie,它就是一个独立的网页。contentscript.js:这个从名字上看就可以发现,它是可以拿到当前页面的内容和信息的,拿cookie的代码就放在这里。但注意,尽管它可以拿到当前打开页面的内容,但它和当前页面加载的js也不是在一个空间里运行的,比如当前页面加载了jQuery,在这个脚本是没法使用jQuery的。background.js:这个就厉害了!顾名思义是在后台运行的,它可以说是连接其他两块的桥梁。在contentscript.js里拿到cookie后可以通过chrome.runtime.sendMessage函数将cookie以消息的形式发给background.js,通过chrome.runtime.onMessage.addListener函数来接收消息。而在popup.js里可以通过chrome.extension.getBackgroundPage函数获取background.js里的变量。这样,contentscript.js里拿到的cookie就可以传递到popup.js里来组装URL访问量子恒道的API了。
根据我的理解,background.js除了作为通信的桥梁以外,一些后台的功能也要放在这里,比如alarm和notification的功能。考虑到量子恒道每天会清空数据,所以每天的23:50分调用Chrome自己的通知提醒功能提醒用户下载今天的数据。因为background.js是Chrome浏览器一打开就会开始运行的,而其他的两个则要等到打开特定页面才会运行。
除此之外,还有options.html用来构造插件的“选项”页面,即在插件图标上点击右键选择“选项”就会跳转到这个页面来。以这个插件为例,选项页面可以配置:下载的字段,是否开启下载提醒,提醒时间等等。这个页面也是一个独立的页面,它将选项存在浏览器的LocalStorage里。这里值得注意,不能直接在options.js里拿window.localStorage来作为存储,因为这是独立的页面,你存在options.html的LocalStorage里别的页面没法拿到!同样这时又是桥梁background.js登场的时候了,在options.js里通过chrome.extension.getBackgroundPage获取background页面的LocalStorage,然后存取选项,这样popup页面才能拿到这些选项组装URL。
文件的下载
拿到了数据下载为什么格式呢?考虑到很多人习惯使用Excel来作数据统计,所以CSV是一个不错的选择,既能够被Excel打开,又是纯粹的文本文件。本来指望通过插件里直接JS来写本地文件,很不幸,虽然Chrome有FileSystem相关的API,但只给Chrome App使用,不给插件(extension)用的,这就需要一个后台了。最终我用Flask写了个后台放在了SAE供这个插件调用,后台的功能非常简单,接收插件端发过来的session然后抓取JSON结果组装成CSV文件。关于这里,有两个点值得说一说:
- 中文编码问题:我电脑上是没有Excel的,用的WPS,打开我生成的CSV没有任何问题。因为我是根据以前的经验全部UTF8来处理中文的,后来有个用户联系我说下载的文件都是乱码,这时我才发现这个问题,原来Excel打开UTF8的文件是有问题的。。。最后只能转换为gbk才算解决。这里推荐一篇关于Python中文编码的文章,分析的很到位。简单来说,Python里认为
unicode才是内部编码,所以unicode才需要调用encode函数转换成GBK/UTF8之类的。所以处理中文是一律使用u''前缀,输出时根据需要转换成其他编码。 - 如何通过点击超链接直接下载流式的数据:由于CSV是后台动态生成的,并不是一直存储在后台服务器上的,我的想法是:用户直接在插件那边点击一个URL,然后直接开始下载。经过搜索,发现只要后台的响应header相应更改即可:
1 | response.headers['Content-type'] = 'text/csv' |
OK!最后放上项目地址:Github