前一段时间写的小东西,一直没工夫把他系统写出来,今天眼睛疼,就写写吧~~(原来博主不蛋疼时也会更新博客的哈~)
python 抓取网页基础
python 自己带有很多网络应用相关的模块,如:ftplib 用于 FTP 相关操作,smtplib 和 poplib 用于收发电子邮件等等,利用这些 模块自己写一个 FTP 软件或是邮件客户端类软件完全是可能的,我就简单的试过完全用 python 脚本收发邮件和操作自己的 FTP 服务器。当然,这都不是今 天的主角,我们今天要用到的几个模块是:urllib,urllib2,cookielib,BeautifulSoup,我们先来简单介绍下。 urllib 和 urllib2 自然都是处理 URL 相关的操作,urllib 可以从指定的 URL 下载文件,或是对一些字符串进行编码解码以使他们成为特定的 URL 串,而 urllib2 则比 urllib 更 2 一点,哦不对,是更牛逼一点。它有各种各样的 Handler 啊,Processor 啊可以处理更复杂的问 题,比如网络认证,使用代理服务器,使用 cookie 等等。第三个 cookielib,顾名思义,专门处理 cookie 相关的操作,其他的我也没深入过。 而最后一个包,BeautifulSoup,“美丽的汤”,它是一个第三方的包,专门用于解析 HTML 和 XML 文件,使用非常之傻瓜,我们就要靠它来解析 网页源代码了,可以从这里下载,当然你也可以用 easy_install 安装它,这里还有它的中文使用文档,有多例子是相当不错的。
我们先来看看最简单的网页抓取,其实网页抓取就是将所要的网页源代码文件下载下来,然后对其分析以提取对自己有用的信息。最简单的抓取用一句话就可以搞定:
1 | import urllib |
这样就会打印出百度首页的 HTML 源码了,还是很 easy 的。urllib 的 urlopen 函数会返回一个“类文件”对象,所以直接调用 read()即可获取里面的内容了。但是这样打印得到的内容是一团糟,排版不好看,编码问题也没解决,所以是看不到中文字符的。这就需要我们的 BeautifulSoup 包了,我们可以使用上面得到的源代码字符串 html_src 来初始化一个 BeautifulSoup 对象:
1 | from BeautifulSoup import BeautifulSoup |
这样,后续处理 HTML 源码的工作交给 parser 变量来负责就好,我们可以简单的调用 parser 的 prettify 函数来相对美观的显示源码, 可以看到这样就能看到中文字符了,因为 BeautifulSoup 能自动处理字符问题,并将返回结果都转化为 Unicode 编码格式。另 外,BeautifulSoup 还能迅速定位到满足条件的指定标签,后面我们会用到~
抓取人人网的新鲜事
前面讲的是最简单的抓取情形了,但通常我们需要面对更复杂的情形,拿人人网来说,需要登录自己的账号才能显示新鲜事,这样我们就只能求助于更 2 一点 的 urllib2 模块了。试想,我们需要一个 opener 来打开你的人人网首页,而为了进入首先就需要认证,而这个登录认证需要 cookie 的支持,那我 们就需要在这个 opener 之上搭建一个处理 cookie 的 Handler:
1 | import urllib,urllib2,cookielib |
首先 import 我们需要的所有模块,然后使用 urllib2 模块的 HTTPCookieProcessor 搭建一个处理 cookie 的 Handler,传入 cookielib 模块的 CookieJar 函数作为参数,这个这个函数处理 HTTP 的 cookie,简单地说,它从 HTTP 请求中 提取 cookie,然后将其返回给 HTTP 响应。然后利用 urllib2 的 build_opener 来建立我们需要的 opener,这个 opener 已经 满足我们处理 cookie 的要求了。
那么这个 Handler 怎么工作呢,前面说了,它需要捕捉到 HTTP 请求才行,也就是说,我们需要知道,登录人人的时候发了什么数据包出去,牛逼的 人可以使用各种命令行抓包工具如 Tcpdump 一类的,我等小民还是图形化的吧。这里我们借助于 Firefox 的 HttpFox 来实现,可以从这里添 加这个牛逼的插件。安装好该插件以后,我们用 Firefox 登录人人网,然后输入自己的账号和密码,然后,别急,不要按登录按钮,从状态栏打开 HttpFox 插件,点击 Start 按钮开始抓包,然后点击人人网的登陆,登陆过程完成后点击 HttpFox 的 Stop 停止抓包,如果一切正常的话应该可 以看到如下信息了。
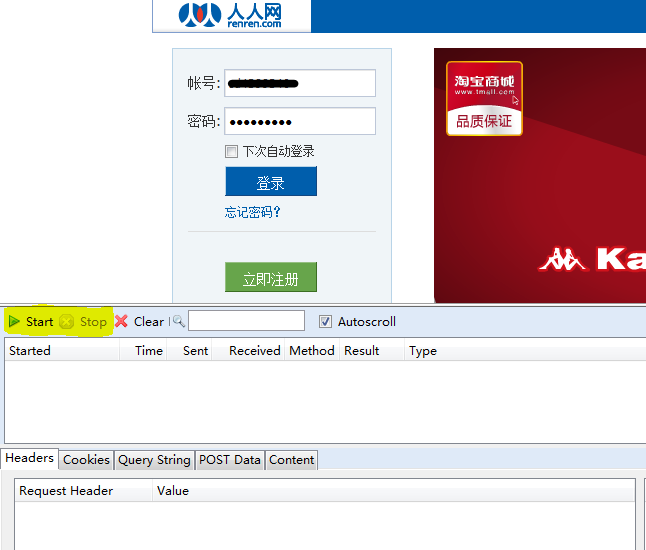
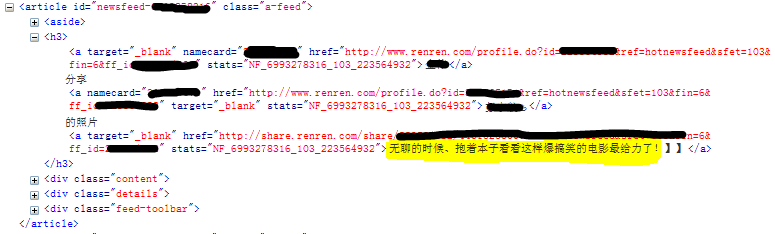
我们可以看到登陆人人的过程中浏览器向人人的服务器发送 POST 请求数据,有四项,其中两项是你的账号和密码。下面我们就利用代码模拟发出同样的请求就可以啦。
1 | post_data = { |
首先,构造一个字典来存储我们刚才抓到的 POST 数据,然后通过 urllib2 的 Request 类来自己构造一个“请求”对象,请求的递交网址就是 上面捕捉的 POST 请求的 URL 部分,后面跟着我们的 POST 数据,注意,这里需要使用 urllib 的 urlencode 方法重新编码,以使其成为合法的 URL 串。下面的过程就跟前面提到的简单抓取过程一样,只不过这里打开的不是简单的网址,而是将网址和 POST 数据封装后的 Request 请求,同样,我 们将源码赋给 BeautifulSoup 以便后面处理。
现在我们的 parser 里存储的就是含有好友新鲜事的网页源码了,我们怎样提取有用的信息呢?分析网页这种粗活还是交给 Firefox 的 FireBug(这里下载)来玩吧。登入你的人人网,随意右击一下新鲜事里某个人的状态,选择“查看元素”,就会蹦出如下窗口,显示出你所点击的部分对应的源码:
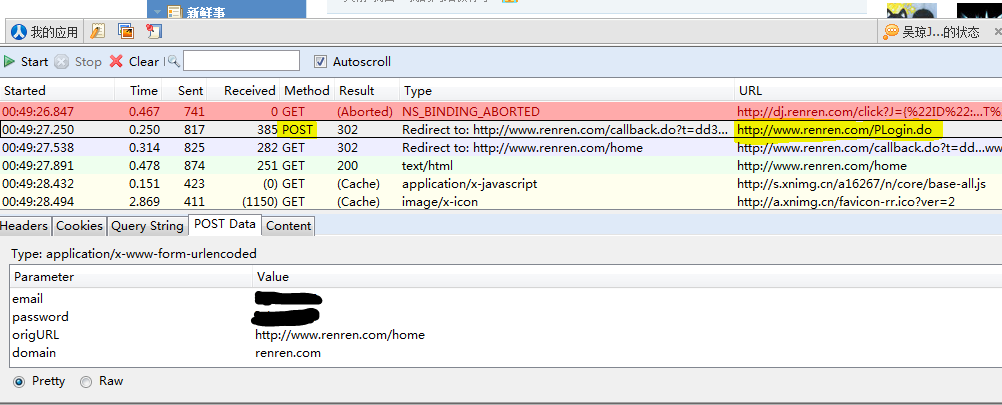
我们可以看到,每个新鲜事对应着 article 标签,我们再仔细看看 article 标签的详细内容:
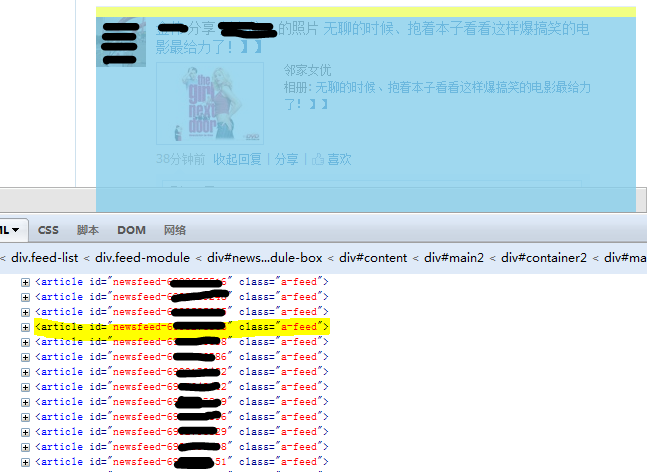
里面的 h3 标签包含了好友的姓名和状态,当然,还有一些肥猪流的表情地址,接触过 HTML 的对这个应该不陌生吧。所以我们要抓的就是这个 h3 啦!
BeautifulSoup 抓取标签内容
下面就是我们的 parser 露脸的时候了,BeautifulSoup 提供了很多定位标签的方法,简单的说,主要就是 find 函数和 findAll 函数了,常用的参数就是 name 和 attrs,一个是标签的名字,一个是标签的属性,name 是个字符串,而 attrs 是个字典,比如说find(‘img’,{‘src’:'abc.jpg’})就会返回类似这样的标签:<img src=”abc.jpg”>。而 find 与 findAll 的区别就是,find 只返回第一个满足要求的标签,而 findAll 返回所有符合要求的 标签的列表。获取标签后,还有很多方便的方法获取子标签,例如,通过点操作符,tag.a 可以获取 tag 所代表的标签下的子标签 a,再如 tag.contents 可以获取其所有孩子的列表,更多应用可以查看它的文档。下面就具体到本例来看怎么抓取我们想要的内容。
1 | article_list = parser.find('div','feed-list').findAll('article') |
这里,我们通过find(‘div’,'feed-list’).findAll(‘article’)获取 class 属性为feed-list的 div 标签,第二个参数直接为一个字符串时代表的就是 CSS 的 class 属性了,然后获取其所有 article 的列表,对照上面的图,这句其 实就是获得了所有新鲜事的列表。然后我们遍历这个列表,对于每个 article 标签再获取其 h3 标签,并提取内容,如果标签中直接含有文本,则可以通过 string 属性获得,最后,我们去掉一些控制字符,如换行一类的。最终将结果打印出来,当然这只能获取一小部分,“更多新鲜事”的功能还不能达到,有兴 趣的继续研究吧,我觉得通过 HttpFox 是不难实现的吧。
团购信息聚合小工具
用同样的知识,我们还可以做一些有趣的应用,像现在很火的团购信息聚合,其实思路还是很容易的,就是分析网站的源代码,提取团购的标题,图片和价格 就好了。这里放出源码文件,有兴趣的可以研究下!用 PyQt 做的界面,按钮的功能还没有实现,只能提取“美团”,“糯米网”,“QQ 团购”三个网站,从下 拉列表框里选择就可显示,图片会保存在本地目录里,来个截图看看吧~

打叉的按钮功能没有实现哦~这里是文件下载,一个 pyw 主窗体文件,两外两个 py 文件一个是 UI,一个是 Resource。