上一篇聊完了单元测试,这一篇来说说 E2E 测试。单元测试着眼的是“关注分离”,测的是一些函数单元是不是工作正常,而 E2E 则是集成测试,从最终用户的角度来进行端到端(End To End)的测试,测一些用户场景是不是正常。这篇文章就来探讨一下写 E2E 测试的最佳实践,本文使用 protractor 2.x 和 jasmine 2.x,但一些思路和想法同样适用于别的框架。
使用 mock API 和非真实后台
这一点其实存在很大争议,很多人觉得 E2E 测试作为集成测试就应该使用纯真实的 server 环境,所有后台 API 都应该实打实。我个人认为 E2E 测试是更偏向于开发者的测试而不是 QA 的测试,QA 的测试当然要“真枪实弹”,但开发者使用 mock API 我觉得更加方便。我认为好处主要有以下几点:
- mock 的 API 不仅可以用于测试,还可以加速开发。现在的 Web 开发早已趋向彻底的前后分离,后端只提供 API,其他的都归前端。前端在开发阶段就需要根据前后端商量好的 contract 来 mock API,使得在后端 API 未完工的情况下可以方便的进行前端的开发。所以 mock 一次,开发和测试阶段都能用,划算啊!
- 迅速解决“前后端撕逼”问题。众所周知,所有的 bug 都是前端 bug,因为 QA 测的是你的前端页面啊,不管 bug 是什么引起的,肯定都是报给前端啊。所以,前端每天要做的一件重要的事就是迅速分辨哪些 bug 是由后端 API 引起的。使用 mock API 跑 E2E 测试,就是要保证在后端 API 正常返回的情况下前端逻辑能正常工作。这样一旦 E2E 测试跑过了,就可以迅速撇清关系:对不起,请把这个 bug assign 给后台修!
- 节约测试成本。使用 mock API 使得 E2E 测试可以跑在自己的开发 server 上,不仅可以减轻测试 server 的压力,更是避免了真实测试环境的一些资源消耗。
- 跑起来速度快!没了真实环境的束缚,API 想几秒返回就几秒返回,测试跑起来自然非常快了。
说完了好处,来说说问题。使用 mock API 带来的最大问题就是,你需要保证你 mock 的逻辑与后台的真实逻辑是相匹配的。比如说,后台有 DB,你也要有一个类似数据库的地方存数据;后台可以根据不同的输入返回正确的值或错误代码,你的 mock 同样需要做到这一点。在谈具体的解决方案之前,让我们先从文件夹结构说起,下图是我在项目中常用的 E2E 文件夹结构:
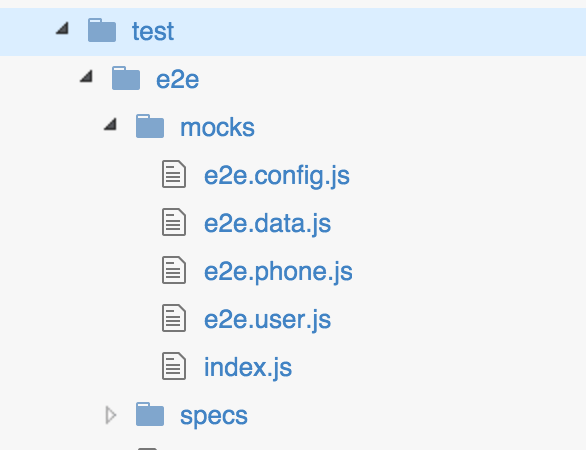
e2e 文件夹下分了 mocks 和 specs 两个目录,specs 不多说,重点看看 mocks 目录。
- index.js:这个文件是“带 mock API 的 app”的入口,来看一个简单的例子:
1 | angular |
其中定义了新的 module,它依赖原始的 app 的 module,并在其上定义一些新的配置和 service。
- e2e.config.js:这是“带 mock API 的 app”的配置,就是上面代码第 6 行的
appTestConfig,一般我们可以用它定义 API 的请求延迟。由于使用了 mock API,HTTP 请求是可以立即返回的,为了让其更逼真,我们可以使用 interceptor 来监听所有/api开头的请求,让其过几秒再返回,以此来模拟真实的环境。
1 | appTestConfig.$inject = ["$httpProvider"]; |
- e2e.data.js:这个文件定义了一个 service(就是 index 里的
MockData),它的作用就是我们前面提到的 DB,它包含 API 要返回的各种数据。之所以将它定义为 service,是利用 service 单例的特性,在 E2E 测试中,只要页面不刷新,前一个请求对数据的写操作就可以反映到后一个请求的读操作中,这样就跟真实环境的 DB 很类似了。 - e2e.phone.js/e2e.user.js:这两个文件分别对应原始 app 中定义的 service,针对每个 service 都要有这么一个文件,这个文件的作用就是 mock 原始 service 里的各种 API 请求。来看一个登录 API 的例子:
1 | userServiceMock.$inject = ["MockData", "$httpBackend"]; |
可以看到,为了让其更逼真,我们可以根据请求发过来的不同数据来 mock 不同的响应,给出不同的错误代码,这样在 E2E 测试里我们就可以模拟更多的用户场景了。
PageObject 应该包含啥
PageObject 是 protractor 官方推荐的最佳实践,它最大的好处就是将页面元素的选择器与测试本身隔离开,这样一旦页面结构发生变化,只需要更新 PageObject 即可,测试部分的代码不用变动。在官方的例子中,PageObject 除了包含元素的定义以外,还包含一个get()函数来加载这个页面,包含两个其他函数来对元素进行输入和获取文字的操作。对于这个例子我持有保留意见,我的看法是好的 PageObject 应该包含以下这些东西:
load()或get()函数,用来加载页面。- 页面上所有测试需要用到的元素。
- 页面测试需要用到的数据,比如测试表单页面时需要填入的测试数据。
- 共享的测试用例,比如多个测试用例可能都需要用到公用的代码来 assert 特定的逻辑,那么这个公用逻辑可以作为函数提出来放入 PageObject。
- 不要包含对元素的操作函数,像官方例子中的函数,只是简单的在元素上调用
.sendKey(xxx)或getText(),我认为没必要将其封装成函数,直接写会更加直观,看测试代码的人也比较容易明白。 - 每个 PageObject 单独放一个文件,然后每个文件 export 这个 class,这样一来,如果其他的 PageObject 依赖这个页面,可以方便的引入。
另外,ES6 让继承写起来更方便了,我们完全可以打开脑洞,给所用的 PageObject 来一个基类:BasePageObject,来看一个例子(完整的实现可以看这里):
1 | class BasePageObject { |
BasePageObject 包含所有 PageObject 都会使用到的公用函数,它的构造函数接收一个 url 作用参数,这个 url 被load()函数使用来加载页面,它是子类继承后在子类构造函数中通过super(xxx)来传入的。另外它调用了一个_getAllElements()的函数获得所有元素的定义并将其挂在this.ele对象上方便使用,而这个_getAllElements也是要靠子类自己来实现的。除此之外,我们看到第 13-17 行定义了四个函数用来获取一些公共的布局组件,因为基本各个页面都包含这些组件,放在基类中子类就可以直接用了。最后基类还包含了公共的测试用例函数assertCorrectLayout(),它接受一个 config。从函数名字就可以大致猜到它的作用:每个页面可能都要测试一些公共的布局,比如页面的 URL、标题是不是正确啊,header 和 footer 显示是否正常,sidebar 和 breadcrumb 导航是不是能正常工作等等。这些测试每个页面都做,所以把它放在基类中,子类只需要传入一个配置对象即可。来看一个子类 PageObject 的例子:
1 | import LoginPage from "./login.page"; |
可以看到,继承了父类后,子类的 PageObject 要做的就是:
- 子类构造函数中调用父类的构造函数并传入自己的 URL。
- 实现
_getAllElements函数,定义自己的页面元素。 - 根绝需要覆盖父类的
load()函数。在这个例子中,假设 phone 页面需要登录后才能查看,那么直接访问/phone就会被重定向到 login 页面,那我们就需要依赖 LoginPageObject 的一些定义和函数,如这里的登录逻辑,成功登录后才能看到自己的页面。所以对于需要登录的页面,我们都要覆盖父类的 load 函数。
load 函数里调用了一些
browser._上的函数,这是我们自己定义的 helper 函数,后面会讲到。
PageObject 里的元素该咋定义
看到这个标题有人会问:这算问题吗?那我换个方式问,挂在this.ele上的(也就是_getAllElements()函数返回的)应该是选择器本身.xxx还是 element 包装过的对象$(.xxx)呢?从使用者的角度讲,当然是包装过的对象了,因为方便直接调用上面的一些函数啊。但有些情况下,你还是需要选择器的,举个例子:一个表格里四行三列,行选择器是.row,列选择器分别是.col1/.col2/.col3等。测试里可能需要验证每一个格子里的文字,我们不可能把 12 个元素都写死放在 ele 变量上,如何更方便的解决这种需求呢?我的方案是这样的:
1 | _getAllElements () { |
可以看到,我们只返回一个row的元素,它是一个对象,里面的 view 属性返回包装过的多个元素($$$$等价于element.all),其他属性则是它的子元素选择器。简单的说,存在多个实例的父元素(如表格的行)我们使用包装过的对象,对于每行的格子我们使用纯选择器。然后具体的测试中我们就可以这么写:
1 | const rowList = page.ele.row; |
遇到存在多个父元素,而每个父元素里又存在很多不同子元素的情况下,可以尝试使用这种方式来定义元素。定义的时候不显得重复,使用的时候也没有很麻烦。
使用 ComponentObject
在前面的文章里我们讲过,在基于组件开发的实践中,页面其实是由各个组件搭成的。那么很自然的,PageObject 也应该由 ComponentObject 来组成。同一个组件在不同的页面上重用时,组件内部的元素肯定都是一样的,一些逻辑也基本一致。所以 ComponentObject 里可以包含这个组件的所有元素以及一些公共的测试用例。考虑到 Component 在重用时,一般父级元素是不一样的,所以在 ComponentObject 的构造函数中可以传入一个 parentElement 的参数用来将组件内的选择器都限定在这个父选择器之内。来看一个例子:
1 | // phone form component object |
可以看到在这个 Form 组件的定义中,组件内所有元素都是定义在传入的父元素的基础上的,这样即便一个页面内有多个同样的组件也不会重复,使用的时候只要传入不同的父级元素即可:
1 | import PhoneFormComp from "./phone-form.comp"; |
善用 helper 函数和自定义 matcher
在写 E2E 测试的时候,我们可能会用到很多工具函数,比如说操作一个 select 框啊,操作一个 DatePicker 啊等等,这些操作可能在多个测试用例里都会用到,那么我们可以直接定义一个E2EHelper的 class 用来存放这些 helper 函数。在 protractor 的配置文件中,我们在 onPrepare 里引入这个 class,并将其定义在browser._上,因为 browser 是所有的 spec 里默认都可以访问到的,所以很多全局变量都可以考虑挂在它上面。这样在 spec 文件的测试里就可以方便的使用browser._.xxx来调用这些函数了。
除了 helper 函数,有的时候我们可能还需要一些自定义的 Matcher 来扩展 jasmine 中没有的功能,比如最常用的判断一个元素是否含有某个 class 样式,与其每次都在测试用例里手写expect(ele.getAttribute('class')).toContain(xxx),不如直接扩展 jasmine 定义自己的 Matcher,语义上更容易理解。Matcher 的定义也非常的简单,下面就是一个例子:
1 | const customMatchers = { |
有了这个定义以后,我们在测试中就可以直接写expect(ele).toHaveClass(xxx)了。网上还有很多成熟的库,包含很多常用的 Matcher,感兴趣的可以索索“protractor custom matcher”。自定义的 Matcher 也需要在 onPrepare 中初始化,我们在里面定义一个 beforeEach 函数,把自定义的 Matcher 加入到 jasmine 中去。看下面的例子,onPrepare 中包含 helper 函数,上一节提到的 BasePageObject,以及自定义的 Matcher。
1 | onPrepare: () => { |
protractor 的大部分函数都返回 promise
这一点可能平时没有注意,其实 protractor 官方的文档里专门有讲这个。也就是说,平时我们使用的.getText(),.isDisplayed(),.getAttribute()等等返回的都是 promise,之所以我们可以直接那么用,是因为 jasmine 的expect()函数真正 expect 的是 promise resolve 后的值。相信平时使用这些函数的时候倒不会犯什么错,最容易犯错的是,定义一些自己的函数时,比如下面的代码
1 | if (ele.isDisplayed()) { |
代码的原意是如果元素显示的话,我们做一些事情,不显示的话我们做别的。但事实是这个 if 判断永远为 true,因为里面是一个 promise!所以正确的写法应该是:
1 | ele.isDisplayed().then(val => { |
要时刻记住 protractor 里绝大部分的函数返回的都是 promise,如果我们自定义的逻辑用到这些函数,就应该以处理 promise 的方式来处理它们。
其它小 tip
最后说一些让 protractor 更加好用的小 tip。
让测试 report 更好看
protractor 默认的测试 report 就是在命令行里输出...F..F..,这么丑的 report 能忍吗?叔能忍婶不能忍啊!在 karma 中我们有 reporter 这个选项,让我们可以配置友好的测试输出,但 protractor 似乎没有这个配置啊。别急,其实早有人解决了这个难题,试试jasmine-spec-reporter吧。你要做的很简单:
1 | // 禁用默认的输出 |
再跑一下测试看看,结果是不是好看多了?
除了这两个选项外,它还支持很多有意思的配置,具体可以探索它的文档。
失败时自动截图
由于测试都是自动化的,一旦跑失败我们除了看 log 找原因以外,如果有截图就更好了。其实截图也属于 reporter 的一种,借助插件protractor-jasmine2-screenshot-reporter我们就可以实现在 E2E 测试失败的时候自动保存当前网页的截图到指定文件夹。它的配置也很简单,与上面的 reporter 类似,也是直接往 onPrepare 里面添加代码:
1 | const HtmlScreenshotReporter = require("protractor-jasmine2-screenshot-reporter"); |
除了截图,它还支持输出 HTML 格式的 report(第 4 行),利用 pathBuilder 函数我们还可以指定截图文件的名称,上例中我们直接将失败的 spec 的 description 作为文件名保存。
ES6 的报错行号
protractor 2.x 需要手动引入 babel 来支持使用 ES6 来书写 spec 文件,至于配置文件本身,只要你的 node 版本够高(4.x)或使用--harmony也是可以用 ES6 来写的。但如果你在 protractor 的配置文件一开头就引入 babelrequire('babel-core/register');就会发现,一旦 spec 报错,log 里给出的报错行号是不对的,在 protractor 的 issues 里有人给出了解决方案,其实只要在 onPrepare 里再引入 babel 即可。